Using Linux Kernel Memory Tiering
- Steve Scargall
- How to , Linux
- June 10, 2022
In this post, I’ll discuss what memory tiering is, why we need it, and how to use the memory tiering feature available in the mainline v5.15 Kernel.
What is Memory Tiering?
With the advent of various new memory types, some systems will have multiple types of memory, e.g. High Bandwidth Memory (HBM), DRAM, Persistent Memory (PMem), CXL and others. The Memory Storage hierarchy should be familiar to you.
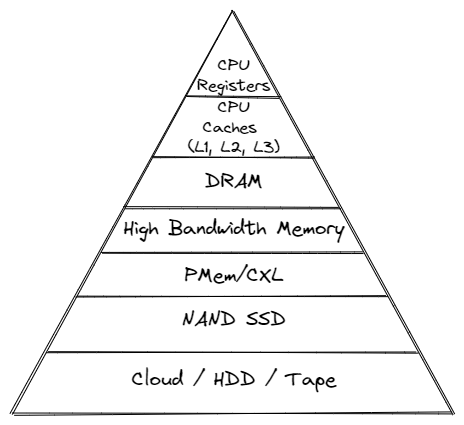
Memory Storage Hierarchy
For this article, I’ll keep the focus to DRAM and Intel Optane Persistent Memory (PMem). The Kernel features we’ll discuss are generic so they’ll work with other memory devices too. In a typical system with DRAM and PMem, the CPUs and the DRAM will be put in one logical NUMA node, while the PMem will be put in another (faked) logical NUMA node. With commit c221c0b0308f (“device-dax: “Hotplug” persistent memory for use like normal RAM”), available from mainline Kernel v5.1 onwards, PMem can be used as cost-effective volatile memory with or without the use of a swap device. In a previous blog post, I describe How To Extend Volatile System Memory (RAM) using Persistent Memory on Linux that uses this “KMemDAX” or “System-RAM” feature. The following examples shows four NUMA nodes, 2 x 192GB DRAM with CPUs and 2 x 32GB memory only (fake) NUMA nodes created from PMem devices (KMemDAX/System-RAM).
# numactl -H
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 0 size: 192115 MB
node 0 free: 164188 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 1 size: 192011 MB
node 1 free: 165112 MB
node 2 cpus:
node 2 size: 311296 MB
node 2 free: 311295 MB
node 3 cpus:
node 3 size: 321536 MB
node 3 free: 321534 MB
node distances:
node 0 1 2 3
0: 10 21 17 28
1: 21 10 28 17
2: 17 28 10 28
3: 28 17 28 10
While useful for some applications and workloads, it’s difficult to control where the data is placed. Once the page is written to the DRAM or PMem, it lives there until the application stops or unmaps the page, or the host is rebooted.
The evolution to the KMemDAX/System-RAM feature is “Kernel Memory Tiering”, “Tiered Kernel Memory”, or “Kernel Tiered Memory” where the Kernel now understands the characteristics of the physical memory devices (NUMA nodes) and can more intelligently place and move data based on capacity and demand (page temperature or color). Device characteristics such as latency are exposed to the Kernel through the System Locality Information Table (SLIT) and Hetrogeneous Memory Access Table (HMAT) within the BIOS, defined in the ACPI specification.
In commit 26aa2d199d6f (“mm/migrate: demote pages during reclaim”), a mechanism to demote the cold DRAM pages to PMem node under memory pressure is upstreamed to Kernel 5.15 onwards. This is the “Kernel Tiered Memory” feature. Using this feature, cold DRAM pages can be demoted to PMem node proactively to free some memory space on DRAM node. In a future Kernel commit, pages resident in PMem that become hot can be promoted to the DRAM node.
To optimize the system performance, hot pages should be placed in the fastest tier, DRAM, and the colder/cooler pages in slower tier(s), PMem. In the existing NUMA balancing code, there are already a set of existing mechanisms to identify the pages recently accessed by the CPUs in a node and migrate the pages to the node. Kernel memory tiering reuses these mechanisms to build the mechanisms to optimize the page placement in the memory tiering system.
Why use Memory Tiering?
There are many reasons to deploy a tiered memory solution which mirror the same/similar reasons why we tier storage, namely:
- DRAM isn’t scaling to meet today’s needs. It is expensive on a dollar-per-gigabyte ($/GiB) and today consumes 30-50% of the Bill of Materials (BOM) cost for a given system
- DDR4 is increasing in cost and DDR5 has a hefty premium for next-gen systems
- Current systems (Intel Ice Lake and Sapphire Rapids) support up to 6TiB of memory per socket - 2TiB of DRAM and 4TiB of Optane PMem.
- DDR has limited capacities (up to 128GB DIMMs)
- PMem has higher capacities at a significantly reduced cost. For example, Intel Optane Persistent Memory is available in 128GB, 256GB, and 512GB modules.
- Displacing DRAM with PMem can provide similar performance for a significant BOM cost saving, or use the same budget to all but double the amount of memory installed in the host.
- There’s a need for more memory capacity, bandwidth, and quality of service (QoS) as CPUs deliver increasing core counts
- Don’t use the expensive memory (DRAM) to store data you infrequently access. Whatever term you use - ‘Active Memory’, ‘Hot Memory’ or ‘Working Set Size’ - For a given application or system wide is usually quite small relative to the dataset(s) being accessed, so keeping the active/hot data in the faster tier (DRAM) while least frequently used data resides in the slightly slower PMem tier - still nanosecond access latency - has a significant advantage over the traditional paging and swapping most people use today.
- Memory hungry applications have access to more memory. Scale-up vs. scale-out.
- Deploy more Virtual Machines or Containers to increase density and reduce the Total Cost of Ownership (TCO)
- … many more
How To Configure and Use Kernel Tiered Memory
I’ll assume you have the following pre-requisites:
- A system with DRAM and Intel Optane Persistent Memory
- A Linux distribution with the Kernel Tiered Memory feature (Mainline Kernel v5.15 or later)
- RHEL/Red Hat Enterprise Linux 9.0 or later (Kernel 5.14.0-70.13.1.el9_0.x86_64 or later)
- Fedora 35 (5.15.0 or later)
- Ubuntu 22.04 (5.15.0 or later)
- Linux Packages:
- ipmctl
- ndctl (with daxctl)
- numactl
For this walk through, I’m using Fedora Server 36 with Kernel 5.18.0
Step 1 - Configure the Intel Optane PMem for AppDirect
Create an Interleaved App Direct goal and reboot for the changes to take effect
sudo ipmctl create -goal PersistentMemoryType=AppDirect
sudo systemctl reboot
Step 2 - Create devdax namespaces
sudo ndctl create-namespace -f --mode devdax --continue
Example:
# sudo ndctl create-namespace -f --mode devdax --continue
{
"dev":"namespace3.0",
"mode":"devdax",
"map":"dev",
"size":"1488.37 GiB (1598.13 GB)",
"uuid":"bdcba8d9-be04-493c-899b-41d8654a0c93",
"daxregion":{
"id":3,
"size":"1488.37 GiB (1598.13 GB)",
"align":2097152,
"devices":[
{
"chardev":"dax3.0",
"size":"1488.37 GiB (1598.13 GB)",
"target_node":3,
"align":2097152,
"mode":"devdax"
}
]
},
"align":2097152
}
{
"dev":"namespace2.0",
"mode":"devdax",
"map":"dev",
"size":"1488.37 GiB (1598.13 GB)",
"uuid":"c751d712-87a1-4d5a-b29e-f340d9a2735f",
"daxregion":{
"id":2,
"size":"1488.37 GiB (1598.13 GB)",
"align":2097152,
"devices":[
{
"chardev":"dax2.0",
"size":"1488.37 GiB (1598.13 GB)",
"target_node":2,
"align":2097152,
"mode":"devdax"
}
]
},
"align":2097152
}
created 2 namespaces
Step 3 - Convert the devdax namespaces to system-ram devices
We need to convert the devdax namespaces to ‘system-ram’ devices so the Kernel can manage them. Read the ‘daxctl-reconfigure-device’ for more information and theory of operation.
sudo daxctl reconfigure-device --mode=system-ram all
If your Kernel supports and defaults to automatically online hotplug memory, you’ll see a message similar to the following:
# daxctl reconfigure-device --mode=system-ram all
dax2.0: error: kernel policy will auto-online memory, aborting
dax3.0: error: kernel policy will auto-online memory, aborting
error reconfiguring devices: Device or resource busy
reconfigured 0 devices
Check your Kernel config to validate if it auto onlines hot plugged memory:
# grep ONLINE /boot/config-$(uname -r)
CONFIG_MEMORY_HOTPLUG_DEFAULT_ONLINE=y
# cat /sys/devices/system/memory/auto_online_blocks
online
Temporarily disable the hotplug memory feature:
# sudo echo offline > /sys/devices/system/memory/auto_online_blocks
# cat /sys/devices/system/memory/auto_online_blocks
offline
Based on the distribution, there may be udev rules that interfere with memory onlining. They may race to online memory into ZONE_NORMAL rather than movable. If this is the case, find and disable any such udev rules.
Re-Run the daxctl command and it should now succeed. Example:
# sudo daxctl reconfigure-device --mode=system-ram all
[...]
reconfigured 2 devices
# sudo daxctl list
[
{
"chardev":"dax2.0",
"size":1598128390144,
"target_node":2,
"align":2097152,
"mode":"system-ram", <-- Expected
"online_memblocks":743,
"total_memblocks":743,
"movable":true <-- Expected
},
{
"chardev":"dax3.0",
"size":1598128390144,
"target_node":3,
"align":2097152,
"mode":"system-ram", <-- Expected
"online_memblocks":743,
"total_memblocks":743,
"movable":true <-- Expected
}
]
Commands such as lsmem should show the DRAM and System-RAM devices
# lsmem
RANGE SIZE STATE REMOVABLE BLOCK
0x0000000000000000-0x000000007fffffff 2G online yes 0
0x0000000100000000-0x00000002ffffffff 8G online yes 2-5
0x0000001300000000-0x000000307fffffff 118G online yes 38-96
0x0000003680000000-0x000001b7ffffffff 1.5T online yes 109-879 <-- System-RAM/PMem
0x000001c800000000-0x000001da7fffffff 74G online yes 912-948
0x000001e080000000-0x00000353ffffffff 1.5T online yes 961-1703 <-- System-RAM/PMem
Memory block size: 2G
Total online memory: 3.2T
Total offline memory: 0B
Step 4 - Configure the Kernel to use the System-RAM devices
[Optional] Disable the disk swap device:
sudo swapoff -a
Enable the demotion feature
# sudo echo 1 > /sys/kernel/mm/numa/demotion_enabled
# cat /sys/kernel/mm/numa/demotion_enabled
true
# echo 2 > /proc/sys/kernel/numa_balancing
From the Kernel ABI Documentation :
/sys/kernel/mm/numa/demotion_enabled Defined on file sysfs-kernel-mm-numa
Enable/disable demoting pages during reclaim
Page migration during reclaim is intended for systems with tiered memory configurations. These systems have multiple types of memory with varied performance characteristics instead of plain NUMA systems where the same kind of memory is found at varied distances. Allowing page migration during reclaim enables these systems to migrate pages from fast tiers to slow tiers when the fast tier is under pressure. This migration is performed before swap. It may move data to a NUMA node that does not fall into the cpuset of the allocating process which might be construed to violate the guarantees of cpusets. This should not be enabled on systems which need strict cpuset location guarantees.
From the Kernel documentation for /proc/sys/kernel :
numa_balancing Enables/disables and configures automatic page fault based NUMA memory balancing. Memory is moved automatically to nodes that access it often. The value to set can be the result of ORing the following:
0 NUMA_BALANCING_DISABLED
1 NUMA_BALANCING_NORMAL
2 NUMA_BALANCING_MEMORY_TIERING
Or NUMA_BALANCING_NORMAL to optimize page placement among different NUMA nodes to reduce remote accessing. On NUMA machines, there is a performance penalty if remote memory is accessed by a CPU. When this feature is enabled the kernel samples what task thread is accessing memory by periodically unmapping pages and later trapping a page fault. At the time of the page fault, it is determined if the data being accessed should be migrated to a local memory node.
The unmapping of pages and trapping faults incur additional overhead that ideally is offset by improved memory locality but there is no universal guarantee. If the target workload is already bound to NUMA nodes then this feature should be disabled.
Or NUMA_BALANCING_MEMORY_TIERING to optimize page placement among different types of memory (represented as different NUMA nodes) to place the hot pages in the fast memory. This is implemented based on unmapping and page fault too.
My system now has four NUMA nodes, two with DRAM (0 & 1), two with PMem/System-RAM (2 & 3):
# numactl -H
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 0 size: 127632 MB
node 0 free: 93832 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 1 size: 128969 MB
node 1 free: 97866 MB
node 2 cpus:
node 2 size: 1521664 MB
node 2 free: 1521664 MB
node 3 cpus:
node 3 size: 1521664 MB
node 3 free: 1521664 MB
node distances:
node 0 1 2 3
0: 10 21 17 28
1: 21 10 28 17
2: 17 28 10 28
3: 28 17 28 10
For Kernels with the promote feature, set the following:
echo 30 > /proc/sys/kernel/numa_balancing_rate_limit_mbps
# optional but recommended
echo 1 > /proc/sys/kernel/numa_balancing_wake_up_kswapd_early
echo 1 > /proc/sys/kernel/numa_balancing_scan_demoted
echo 16 > /proc/sys/kernel/numa_balancing_demoted_threshold
Monitoring Page Demotion and Promotion
Like all good custodians of our systems, we want to know when pages are being promoted and demoted. The number of promoted pages can be checked by the following counters in /proc/vmstat or /sys/devices/system/node/node[n]/vmstat:
pgpromote_success
The number of pages demoted can be checked by the following counters:
pgdemote_kswapd
pgdemote_direct
The page number of failure in promotion could be checked by the following counters:
pgmigrate_fail_dst_node_fail
pgmigrate_fail_numa_isolate_fail
pgmigrate_fail_nomem_fail
pgmigrate_fail_refcount_fail
Example
# grep -E "pgdemote|pgpromote|pgmigrate" /proc/vmstat
pgpromote_success 0
pgdemote_kswapd 0
pgdemote_direct 0
Note:
The instructions in Steps 3 & 4 are not persistent across system reboots, so you need to create a systemd.service or init.d script to instantiate the configuration at each boot.
Enjoy
Now that your system is capable of tiering data between DRAM and PMem, you can enjoy the benefits of more memory in your system.