Featured

Linux NUMA Distances Explained
TL;DR: The memory latency distances between a node and itself is normalized to 10 (1.0x). Every other distance is scaled relative to that 10 base value. For example, the distance between NUMA Node 0 and 1 is 21 (2.1x), meaning if node 0 accesses memory on node 1 or vice versa, the access latency will be 2.1x more than for local memory.
Introduction
Non-Uniform Memory Access (NUMA) is a multiprocessor model in which each processor is connected to dedicated memory but may access memory attached to other processors in the system. To date, we’ve commonly used DRAM for main memory, but next-gen platforms will begin offering High-Bandwidth Memory (HBM) and Compute Express Link (CXL) attached memory. Accessing remote (to the CPU) memory takes much longer than accessing local memory, and not all remote memory has the same access latency. Depending on how the memory architecture is configured, NUMA nodes can be multiple hops away with each hop adding more latency. HBM and CXL devices will appear as memory-only (CPU-less) NUMA nodes.
Read More
Using Linux Kernel Memory Tiering
In this post, I’ll discuss what memory tiering is, why we need it, and how to use the memory tiering feature available in the mainline v5.15 Kernel.
What is Memory Tiering?
With the advent of various new memory types, some systems will have multiple types of memory, e.g. High Bandwidth Memory (HBM), DRAM, Persistent Memory (PMem), CXL and others. The Memory Storage hierarchy should be familiar to you.
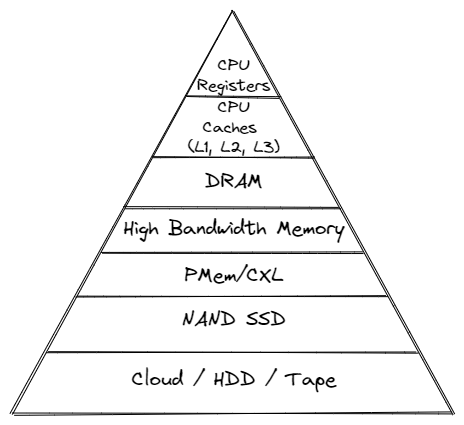
Memory Storage Hierarchy
Read MoreHow To Emulate CXL Devices using KVM and QEMU
What is CXL?
Compute Express Link (CXL) is an open standard for high-speed central processing unit-to-device and CPU-to-memory connections, designed for high-performance data center computers. CXL is built on the PCI Express physical and electrical interface with protocols in three areas: input/output, memory, and cache coherence.
CXL is designed to be an industry open standard interface for high-speed communications, as accelerators are increasingly used to complement CPUs in support of emerging applications such as Artificial Intelligence and Machine Learning.
Read More